从 SVM的那几张图可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题(少部分例外,例如垃圾邮件过滤,就只需要确定“是”还是“不是”垃圾邮件),比如文本分类,比如数字识别。如何由两类分类器得到多类分类器,就是一个值得研究的问题。
还以文本分类为例,现成的方法有很多,其中一种一劳永逸的方法,就是真的一次性考虑所有样本,并求解一个多目标函数的优化问题,一次性得到多个分类面,就像下图这样:
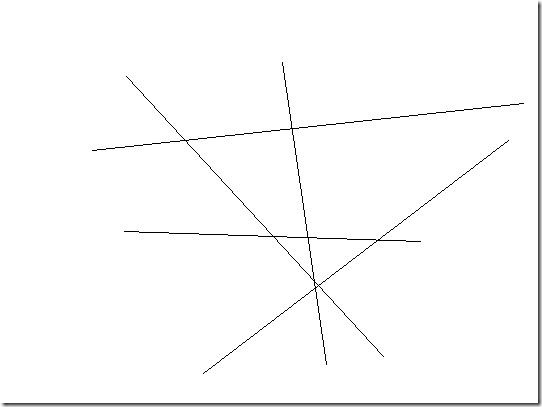
多个超平面把空间划分为多个区域,每个区域对应一个类别,给一篇文章,看它落在哪个区域就知道了它的分类。
看起来很美对不对?只可惜这种算法还基本停留在纸面上,因为一次性求解的方法计算量实在太大,大到无法实用的地步。
稍稍退一步,我们就会想到所谓“一类对其余”的方法,就是每次仍然解一个两类分类的问题。比如我们有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的;第二次我们把类别2 的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。到了有文章需要分类的时候,我们就拿着这篇文章挨个分类器的问:是属于你的么?是属于你的么?哪个分类器点头说是了,文章的类别就确定了。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道了结果)。但有时也会出现两种很尴尬的情况,例如拿一篇文章问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个。不可分类现象就着实难办了,只能把它分给第6个类别了……更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了上一节所说的“数据集偏斜”问题。
因此我们还得再退一步,还是解两类分类问题,还是每次选一个类的样本作正类样本,而负类样本则变成只选一个类(称为“一对一单挑”的方法,哦,不对,没有单挑,就是“一对一”的方法,呵呵),这就避免了偏斜。因此过程就是算出这样一些分类器,第一个只回答“是第1类还是第2类”,第二个只回答“是第1类还是第3类”,第三个只回答“是第1类还是第4类”,如此下去,你也可以马上得出,这样的分类器应该有5 X 4/2=10个(通式是,如果有k个类别,则总的两类分类器数目为k(k-1)/2)。虽然分类器的数目多了,但是在训练阶段(也就是算出这些分类器的分类平面时)所用的总时间却比“一类对其余”方法少很多,在真正用来分类的时候,把一篇文章扔给所有分类器,第一个分类器会投票说它是“1”或者“2”,第二个会说它是“1”或者“3”,让每一个都投上自己的一票,最后统计票数,如果类别“1”得票最多,就判这篇文章属于第1类。这种方法显然也会有分类重叠的现象,但不会有不可分类现象,因为总不可能所有类别的票数都是0。看起来够好么?其实不然,想想分类一篇文章,我们调用了多少个分类器?10个,这还是类别数为5的时候,类别数如果是1000,要调用的分类器数目会上升至约500,000个(类别数的平方量级)。这如何是好?
看来我们必须再退一步,在分类的时候下功夫,我们还是像一对一方法那样来训练,只是在对一篇文章进行分类之前,我们先按照下面图的样子来组织分类器(如你所见,这是一个有向无环图,因此这种方法也叫做DAG SVM)
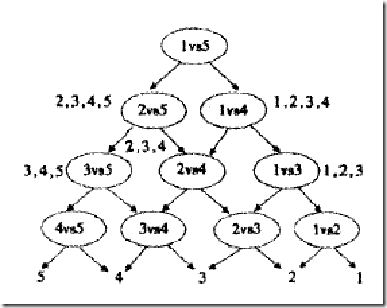
这样在分类时,我们就可以先问分类器“1对5”(意思是它能够回答“是第1类还是第5类”),如果它回答5,我们就往左走,再问“2对5”这个分类器,如果它还说是“5”,我们就继续往左走,这样一直问下去,就可以得到分类结果。好处在哪?我们其实只调用了4个分类器(如果类别数是k,则只调用k-1个),分类速度飞快,且没有分类重叠和不可分类现象!缺点在哪?假如最一开始的分类器回答错误(明明是类别1的文章,它说成了5),那么后面的分类器是无论如何也无法纠正它的错误的(因为后面的分类器压根没有出现“1”这个类别标签),其实对下面每一层的分类器都存在这种错误向下累积的现象。。
不过不要被DAG方法的错误累积吓倒,错误累积在一对其余和一对一方法中也都存在,DAG方法好于它们的地方就在于,累积的上限,不管是大是小,总是有定论的,有理论证明。而一对其余和一对一方法中,尽管每一个两类分类器的泛化误差限是知道的,但是合起来做多类分类的时候,误差上界是多少,没人知道,这意味着准确率低到0也是有可能的,这多让人郁闷。
而且现在DAG方法根节点的选取(也就是如何选第一个参与分类的分类器),也有一些方法可以改善整体效果,我们总希望根节点少犯错误为好,因此参与第一次分类的两个类别,最好是差别特别特别大,大到以至于不太可能把他们分错;或者我们就总取在两类分类中正确率最高的那个分类器作根节点,或者我们让两类分类器在分类的时候,不光输出类别的标签,还输出一个类似“置信度”的东东,当它对自己的结果不太自信的时候,我们就不光按照它的输出走,把它旁边的那条路也走一走,等等。
使用SVM进行分类的时候,实际上是训练和分类两个完全不同的过程,因而讨论复杂度就不能一概而论,我们这里所说的主要是训练阶段的复杂度,即解那个二次规划问题的复杂度。对这个问题的解,基本上要划分为两大块,解析解和数值解。
解析解就是理论上的解,它的形式是表达式,因此它是精确的,一个问题只要有解(无解的问题还跟着掺和什么呀,哈哈),那它的解析解是一定存在的。当然存在是一回事,能够解出来,或者可以在可以承受的时间范围内解出来,就是另一回事了。对SVM来说,求得解析解的时间复杂度最坏可以达到O(Nsv3),其中Nsv是支持向量的个数,而虽然没有固定的比例,但支持向量的个数多少也和训练集的大小有关。
数值解就是可以使用的解,是一个一个的数,往往都是近似解。求数值解的过程非常像穷举法,从一个数开始,试一试它当解效果怎样,不满足一定条件(叫做停机条件,就是满足这个以后就认为解足够精确了,不需要继续算下去了)就试下一个,当然下一个数不是乱选的,也有一定章法可循。有的算法,每次只尝试一个数,有的就尝试多个,而且找下一个数字(或下一组数)的方法也各不相同,停机条件也各不相同,最终得到的解精度也各不相同,可见对求数值解的复杂度的讨论不能脱开具体的算法。
一个具体的算法,Bunch-Kaufman训练算法,典型的时间复杂度在O(Nsv3+LNsv2+dLNsv)和O(dL2)之间,其中Nsv是支持向量的个数,L是训练集样本的个数,d是每个样本的维数(原始的维数,没有经过向高维空间映射之前的维数)。复杂度会有变化,是因为它不光跟输入问题的规模有关(不光和样本的数量,维数有关),也和问题最终的解有关(即支持向量有关),如果支持向量比较少,过程会快很多,如果支持向量很多,接近于样本的数量,就会产生O(dL2)这个十分糟糕的结果(给10,000个样本,每个样本1000维,基本就不用算了,算不出来,呵呵,而这种输入规模对文本分类来说太正常了)。
这样再回头看就会明白为什么一对一方法尽管要训练的两类分类器数量多,但总时间实际上比一对其余方法要少了,因为一对其余方法每次训练都考虑了所有样本(只是每次把不同的部分划分为正类或者负类而已),自然慢上很多。
近期评论